
I have better things to do. Is that on tonight? I forgot and now it’s half over. I can watch it later, on demand. I’m an adult, I won’t let them dictate when I can and can’t do something!
At one point or another on Sunday night (April 15, 2019), all of these thoughts ran through my head regarding the final series premiere of HBO’s Game of Thrones (GoT). In the end, I didn’t watch the episode until the following evening…
Of course, on Monday morning, the inevitable problem was: how to avoid spoilers. Work from home – check. Don’t look at the news – check. Carefully squint reading Slack messages so, just in case, I can look away at the first sign of spoilers – check.
Now, I don’t spend a lot of time looking at social media (i.e. Twitter) during the work day. But, it happens and it’s essentially non-negotiable (my Twitter timeline is mostly work-related anyways, so yeah, it’s all good). Twitter does allow term-specific muting, but it is difficult to filter using the relevant keywords without knowledge of the episode. See the episode, “The Door,” in which a beloved, yet minor, character’s role precipitates a noticeable spike in name usage.
So, the question became: how do I identify relevant episode-specific terms to mute, without reading the terms myself?
Perhaps a computer could do it for me. The approach I explored, and will describe below, was—buzzword alert—natural language processing (NLP), a subfield of artificial intelligence.
Collect the corpus
Much of NLP relies on a corpus, a fancy term for a list of relevant words or documents. In this case, I am interested in the language being used in recent tweets about GoT, which I will collect, and store as my corpus.
I collected content using Python and the Twitter REST API, which requires a Twitter Developer Account.
Import modules:
import requests
import json
import pandas as pd
import re
import timePrepare a pandas DataFrame to hold incoming tweets:
master_corpus_file = 'master_corpus_s08e01.csv' # a local file to store tweets
try:
# if the csv already exists, read to pandas dataframe
corpus_df = pd.read_csv(master_corpus_file, index_col=0)
corpus_max_id = corpus_df['id'].max()
except:
# if the csv does not exist, create a new pandas dataframe
corpus_df = pd.DataFrame(columns=['text', 'id'])
corpus_df.to_csv(master_corpus_file)
corpus_max_id = 0Create a function to request more tweets:
def request_tweets(headers, corpus_max_id):
result = requests.get(
'https://api.twitter.com/1.1/search/tweets.json',
params={
'q': 'gameofthrones', # search term
'result_type': 'recent',
'count': '100',
'lang': 'en',
'since_id': corpus_max_id
},
headers=headers
)
result_json = json.loads(result.text)
return result_json['statuses']Make a function to format incoming tweets into a pandas DataFrame, while ignoring duplicates:
def tweets_to_df(tweets, corpus_df):
data = []
added_text = []
dups = 0
for i in tweets:
no_urls = re.sub(r'https?://\S+', '', i['text']).strip()
if len(corpus_df.loc[corpus_df['text'] == no_urls]) == 0 and no_urls not in added_text:
data.append([no_urls, i['id']])
added_text.append(no_urls)
else:
dups += 1
print('new:', len(added_text), 'dups:', dups)
return pd.DataFrame(data, columns=['text', 'id'])Produce a function that will append the pandas DataFrame contents to the file:
def write_df_to_csv(current_df, master_corpus_file):
with open(master_corpus_file, 'a') as f:
current_df.to_csv(f, header=False)Create a function that calls the above functions, requesting tweets, formatting tweets, and writing the results to disk:
def gather_corpus(corpus_df, corpus_max_id, master_corpus_file, headers):
tweets = request_tweets(headers, corpus_max_id)
current_df = tweets_to_df(tweets, corpus_df)
write_df_to_csv(current_df, master_corpus_file)
corpus_df = corpus_df.append(current_df, ignore_index=True)
return corpus_dfCollect tweets every so often to build up a corpus to your liking:
headers = {
'Authorization': 'Bearer YOUR_TWITTER_API_BEARER_TOKEN'
}
for i in range(100): # run some number of times
corpus_df = gather_corpus(corpus_df, corpus_max_id, master_corpus_file, headers)
corpus_max_id = corpus_df['id'].max()
time.sleep(30) # sleep some number of secondsUsing the code above, I collected about 1800 unique tweets over a span of about 2 hours, spread across three days. You could poll more frequently, and would likely want to use a larger collection of tweets for a proper project, but this is enough to get started.
Inspect the corpus (basic)
Import modules and read the tweets collected above, into a pandas DataFrame:
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
master_corpus_file = 'master_corpus_s08e01.csv'
corpus_df = pd.read_csv(master_corpus_file, index_col=0)Stop words are those that you want to ignore because they contain no useful information. I have listed several common words (or other “tokens” like https) that appeared in the tweets that did not contribute useful information. I also listed incarnations of “gameofthrones,” which because it was my search term, appears in every tweet, and contributes nothing to the analysis.
stop_words = [
'the', 'to', 'this', 'of', 'and', 'that', 'co', 'rt', 'https', 'you', 'is', 'for', 'in', 'it', 'has', 'on', 'with', 'no', 'me', 'he', 'she', 'as', 'all', 've', 'we', 'at', 'by', 'are', 'your', 'have', 'my', 'been', 're', 'without', 'when', 'one', 'next', 'know', 'if', 'but', 'so', 'was', 'nobody', 'be', 'who', 'not', 'can', 'her', 'just', 'don', 'here', 'out', 'want', 'like', 'his', 'about', 'how', 'they', 'from', 'only', 'what', 'best', 'back', 'a', 'i', 'up', 'get', 'gameofthrones', '#gameofthrones', '@gameofthrones'
]We can use scikit-learn’s CountVectorizer to transform our corpus into token counts. In this case, a “token” is a word. Below, vectorizer starts off with the rules from which to build our vocabulary dictionary (like how to split the tweets into words, how to handle punctuation, and which stop words to ignore).
Once through fit_transform, the vectorizer also contains a vocabulary (a numerical mapping to tokens). The result of fit_transform (X_train_counts) is a matrix of counts, with rows (one for each tweet) and columns (one column for each token in the entire vocabulary).
vectorizer = CountVectorizer(stop_words=stop_words)
X_train_counts = vectorizer.fit_transform(corpus_df['text'])To visualize token counts, we can construct a graph like below, where individual word frequencies respond to the number of tweets inspected. Notice that some words are used much more often than others.

Using these raw counts, we can create a list of terms that are common across many tweets. Annoyingly, I collected some tweets before and after Donald Trump made a Game of Thrones-themed tweet, so that has somewhat derailed my sample (e.g. popular tokens “angelabelcamino”, someone persistently anti-Trump, and “realdonaldtrump”, a notorious Trump supporter):
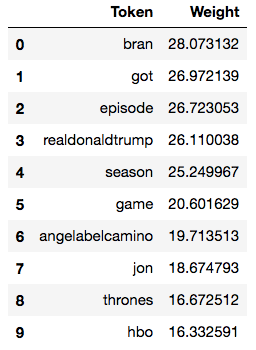
To this point, we have performed what’s known as a “bag of words” analysis; enumerating words thrown into a pile. We could stop here, with a list of words related to recent tweets, muting the top X tokens from our list on Twitter to avoid spoilers, but let’s explore a little more.
Side-note: I was expecting, and disappointed not to find, a stronger episode-specific component in this list. For example (red-herring spoiler alert), the terms “elephant” and “elephants” had 3 and 10 occurrences, placing them tied for 909th and 245th most frequent, respectively. It could be that there was nothing obviously identified by a special term in this episode.
Inspect the corpus (enhanced)
If we wanted to use our tweets in a classifier (e.g. to classify the meaning of a tweet), the raw counts above would favour more common, frequent terms and obscure more interesting, rare tokens. We can rebalance the weightings into “term frequency-inverse document frequency” (tf-idf) features. Tf-idf features promote rare tokens, while penalizing common tokens.
Import additional modules and transform the counts derived earlier:
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)This results in a redistributed token list:
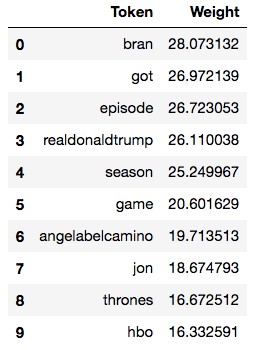
We can do more than list tokens. We can start to understand groupings, perhaps getting a deeper understanding of common themes, or topics. We’ll use a different module for this, called gensim.
Import modules:
from gensim import corpora, models, similarities, matutilsCreate a gensim corpus from the sklearn-derived counts above:
corpus_vect_gensim = matutils.Sparse2Corpus(X_train_counts, documents_columns=False)Transform the corpus into tf-idf features, similar to above:
tfidf = models.TfidfModel(corpus_vect_gensim)
corpus_tfidf = tfidf[corpus_vect_gensim]We can further transform the tf-idf features into Latent Semantic Indexing (LSI) features. LSI features identify clusters of related words, called topics.
id2word = dict((v, k) for k, v in vectorizer.vocabulary_.items())
lsi = models.LsiModel(corpus_tfidf, id2word=id2word, num_topics=300)
corpus_lsi = lsi[corpus_tfidf]Printing the top LSI topics reveals the most obvious conceptual clusters in our corpus:
lsi.print_topics(3)
[(0,
'0.533*"realdonaldtrump" + 0.495*"angelabelcamino" + 0.238*"987karim987" + 0.232*"thechrissuprun" + 0.157*"altcybercommand" + 0.138*"sue" + 0.129*"bran" + 0.121*"momofboys0406" + 0.112*"episode" + 0.110*"paslapatate"'),
(1,
'0.329*"bran" + 0.291*"episode" + -0.250*"angelabelcamino" + 0.247*"season" + -0.243*"realdonaldtrump" + 0.160*"jaime" + 0.157*"game" + 0.145*"stark" + -0.143*"987karim987" + 0.139*"thrones"'),
(2,
'0.414*"throne" + 0.379*"iron" + 0.358*"sit" + 0.323*"selected" + -0.252*"season" + -0.185*"episode" + 0.182*"stark" + -0.180*"game" + 0.176*"jon" + -0.165*"thrones"')]Large positive values reflect a strong presence of the word in the concept, while large negative values indicate a strong absence of the word in the concept. Now, you can start to understand some of what is happening in our corpus.
The first topic contains at least seven Twitter handles, one of them being “realdonaldtrump”. I would wager good money that this cluster contains a healthy dollop of argumentative content, unrelated directly to GoT.
The second topic indicates a presence of the tokens [bran, episode, season, jaime, game, stark, thrones] and absence of three Twitter handles from the first topic, so I would guess this content does pertain to the show.
The third topic indicates a presence of the tokens [throne, iron, sit, selected, stark, jon] and absence of [season, episode, game, thrones]. This is borne out by the fact that AT&T is running a promotion which auto-tweets on behalf of the user, “I’ve selected [character name] to sit on the iron throne”.
Such topic analysis is unsupervised, that is, we have not guided the system into producing predefined concept groupings. The value of unsupervised classification is that it is free to aggregate the data logically, even if not obvious. For example, the AT&T promotion was not obvious until after first inspecting the topics, then the contributing social media content. The beauty of this particular topic is that we have extracted an important insight from the overall aggregation, information that was not obvious inspecting individual pieces of content.
Conclusion
NLP is a deep and rich topic and this article only scratches the surface.
If you’ve made it this far, I assume you’ve learned several things:
- NLP can be used to find a signal in the noise, even in an environment as chaotic and unstructured as Twitter
- There are a variety of mature and capable Python modules available to help you pursue NLP analysis
- Okay, okay, there may be times where I can’t see the forest for the trees. Perhaps I could have avoided Twitter for a day, or muted the hashtag #gameofthrones. Maybe next time…
Obviously, NLP is not limited to GoT. It is equally applicable to catching spoilers for Avengers: Endgame (April 26), X-Men: Dark Phoenix (June 7), or Downton Abbey (September 13). Don’t stop at social media either; NLP can be applied to written documents of any type.
Of course, as part of a geospatial organization, I would be remiss if I didn’t point out that this type of analysis is relevant in a spatial context. If you know where an event is happening, you can find out what people are saying about it. Conversely, if you notice that people are talking about something, you may be able to locate where it’s happening.
Let us know if you’d like to discuss this technique, or others, in order to get the most value from your data!