
We’re going to talk about a DuckDB-Wasm web mapping experiment with Parquet. But first we need some context!
Common Patterns
Every application is different, and most architectures are unique in some way, but we sometimes see common patterns repeated. The diagram below shows a common pattern in web mapping.
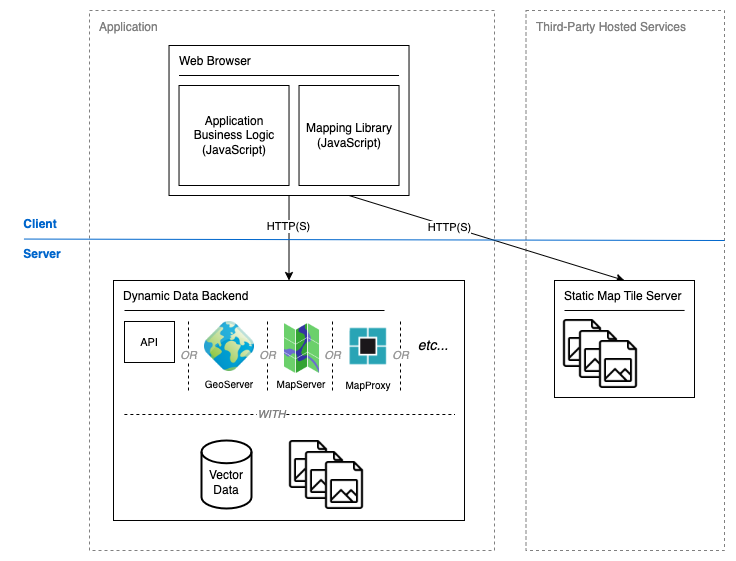
Figure 1: A common high-level architecture for a web mapping platform
A browser-based client presents data provided by two or more sources. A tiled base map is typically supplied by a third-party service to provide locational context. This is static pre-generated data that does not require processing. A dynamic data source typically helps to provide the map’s analytical value. Dynamic data may:
- Be filtered or derived based on user-supplied criteria,
- Need to be rendered to an image depending on the data and use-case, or
- Come from a large dataset that is relatively static and requires dynamic filtering to provide value for the user.
This pattern is effective but the dynamic data source is a bottleneck that can limit scalability. If we assume uniform behaviour across users then the load placed on the dynamic data source is proportional to the number of concurrent users. Some use-cases may support work avoidance through caching strategies or pre-generated responses, though this is not always an option. The number of permutations in filtering or rendering criteria might make caching or pre-generation impractical.
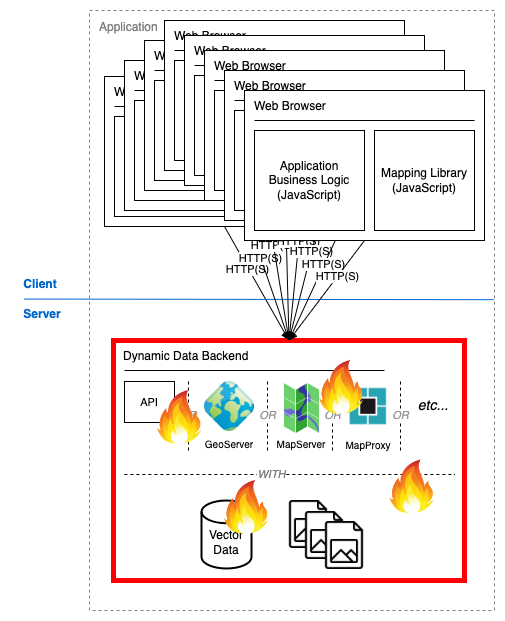
Figure 2: The dynamic data source can become overloaded with too many concurrent users
One solution to an overloaded dynamic data source is a scalable architecture coupled with a deployment that scales on demand. This is where things can get more complicated. Scaling is not rocket science but that doesn’t mean it’s easy and it certainly doesn’t come for free. We can do it, but sometimes we don’t want to solve the world’s problems. Sometimes we just want to put a quick map up on the internet.
Filtered Vector Data
From this point we will focus on a scenario with a large and relatively static vector dataset that must be filtered using user-supplied criteria.
Depending on the use-case and data characteristics we might move data to the client. A client can download a reasonable volume of data from storage in a compatible format and perform all filtering locally. This may be effective up to a point. Each client’s capabilities differ, but it is generally not a good idea to download hundreds of megabytes (or more) of data to a browser. If bandwidth constraints don’t ruin the user experience then the compute demands of parsing that data probably will. So what can we do?
Enter… DuckDB?
If you spend a lot of time thinking about data this is probably not your first encounter with DuckDB. This product has been consistently generating buzz since its release in 2019 and for good reason. Chris Holmes has already done a great job describing its potential value in and beyond geospatial and we don’t need to repeat what has already been said. What specifically interests us here is the httpfs extension.
🚨WARNING: Everything that follows is experimental. This approach is not recommended and more work is required to determine how, or even if, the approach could be applied in production. This is research, not advice!
DuckDB supports the Parquet cloud-native file format and using the httpfs extension can query a remote Parquet file using HTTP range requests. If you’re unfamiliar with range requests they allow us to retrieve a range of bytes from a remote resource, rather than the entire resource. This is pretty great in itself, but it gets better when we learn that the DuckDB-Wasm binary supports the same capability. The WebAssembly binary can be loaded in a browser, so web applications can query remote Parquet files with SQL. DuckDB-Wasm does not currently support DuckDB’s spatial extension. While this does make it harder to approach some geospatial problems there is still plenty of scope for a good Proof-of-Concept (PoC).
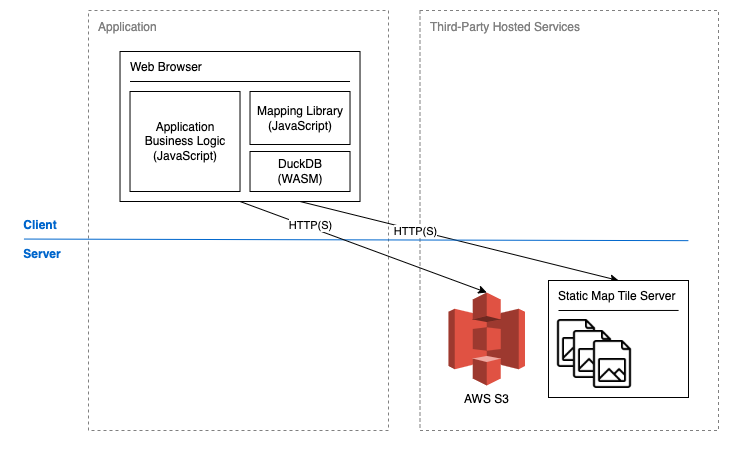
Figure 3: A static data source is queried dynamically
Prototype
The following demo shows a prototype map application running locally. Data points are clustered according to 256 x 256px tiles, with cluster locations at the points’ centre mass. Sparkgeo’s Tile ID layer is briefly added to show tile boundaries. If a tile’s point count falls below a hard-coded threshold, or the map is zoomed beyond a hard-coded threshold, individual data points are shown. As we zoom out of the map (towards the end of the demo) data retrieval performance is adversely affected. This is a limitation of the approach, as more data must be queried at lower zoom levels. However after certain HTTP range request responses have been cached performance will improve considerably. Some use-cases may support only showing data beyond a threshold zoom level to avoid such performance concerns.
The core value of this approach is concurrent user scalability. Although performance (with uncached data) isn’t revolutionary we expect that performance to remain consistent as the concurrent user count grows. If we assume that both the static Parquet data and the static front end resources are hosted on AWS S3 then the only limit on scalability is S3. S3 scales very well. At this point it’s worth comparing with other approaches to cloud-native vector data, for example using FlatGeobuf and Vector Tiles.
Alternate Approaches
FlatGeobuf is a cloud-native file format that supports spatial filtering of features. Given a bounding box we can request data for intersecting features using HTTP range requests. We’ve previously written about FlatGeobuf in web mapping here. This approach has some advantages, but can also suffer at lower zoom levels. We get all data about all features in the bounding box. As the bounding box grows the response payload grows, as does the parsing and rendering load placed on the browser. There is no ability to limit which attributes are returned with each feature. DuckDB lets us choose which attributes to query and attempts to pull data selectively from Parquet.
Vector tiles are another great approach for this type of problem. By creating tiles at discrete zoom levels we avoid the problem of data volume scaling by zoom level. With a static pre-generated vector tileset we could see excellent performance in the client, though we lose some flexibility. The data available to us is determined at the time of tile generation. Any need to dynamically aggregate or derive attribute data must be managed by the developer in front end code. Even a simple question such as “how many data points are in the visible area?” could present a challenge. DuckDB provides great flexibility here via SQL.
Before we get too excited let’s talk about the downsides.
Constraints and Risks
There are a number of constraints and risks to consider. This approach:
- Supports read-only access. DuckDB’s httpfs extension does not currently support write access.
- Is suited to a point dataset. Without DuckDB’s spatial extension all geospatial filtering is performed by comparing a point’s longitude and latitude to the bounds of the current map view. Linestrings, polygons, and multi-part geometries will not be as easy to work with.
- Requires a stable network with good bandwidth. DuckDB → Parquet via httpfs is quite chatty.
- Carries a significant payload. The DuckDB-Wasm “eh” binary is 33.3MB. It may be possible to compile a smaller and more targeted binary for this use-case.
- Does not necessarily scale well to higher data volumes. Reasonable performance has been observed with 4,400,000 data points and >30 attributes. Larger data sets, or potentially smaller data sets with different characteristics, may result in significantly different performance.
- Does not offer obvious optimisations. The overloaded backend scenario shown in Figure 2 is bad, but it’s not insurmountable. Infrastructure could be scaled, and different tooling might improve performance. If DuckDB → Parquet via httpfs hits its performance limit there might be no good options beyond rearchitecting the system, or asking the user to upgrade their network connection. It may be possible to optimise file structures, and multiple versions of the data could be optimised for different query types, but this area requires further research.
All that being said, we think it’s a pretty neat PoC.
Next Steps
DuckDB does – in theory – support remote access of its own DuckDB file type. Testing indicates that this is not currently stable enough for inclusion in a PoC. We’ll keep a close eye on progress here. Remote DuckDB file access could potentially offer advantages over remote Parquet file access.
DuckDB-Wasm binary size is a concern for a web application. The potential for a smaller binary warrants further investigation.
More testing is required to understand how, or if, data can be further optimised within the Parquet file format to better support this approach.
We’re not quite ready to Open Source the code for this experiment yet. We like to thoroughly cross our Ts and dot our lower-case Js before pushing code out into the world, and we’re not there yet. We hope to get there soon.