In a world where geospatial technology continues to evolve, we try to place ourselves at the intersection of innovation and inclusivity. We often imagine a map as a visual guide, but there are opportunities to make this information more accessible to everyone, including those with visual impairments. Today, we explore the concept of map-to-speech technology, where geospatial expertise meets accessibility, creating an enriching experience for users of all abilities.
Understanding Map-to-Speech Technology
Sparkgeo has a record of exploring map accessibility:
Our recent experiment involves transforming maps into an auditory or textual experience, a journey we’re excited to share. We have shared an example demonstration repo on GitHub here, but the method works with any map, or indeed, any visual HTML element that can be exported as an image.
Below is an example video showing the map-to-speech method. The video shows two examples of adding text and speech descriptions to a web map. In each example, the user pans and zooms into an area of interest and then clicks on a button to fetch a voice and text description of the map view. After a few seconds, a text box at the bottom of the screen populates with a text description, and a voice begins reading the description out loud. The method is shown to work in both residential and rural areas.
The process is as follows:
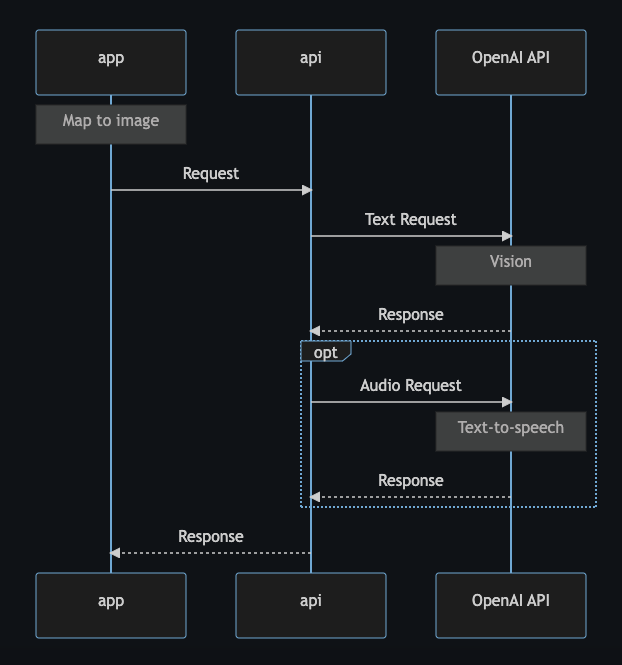
- At the desired time (in the example, when the user clicks a button), users can trigger the map-to-speech process.
- Once the process is started, the frontend is responsible for converting the map to an image. In the example, using Mapbox GL JS, we can convert the map object’s canvas to a data URL (a URL containing the actual image data) using the function chain:
map.getCanvas().toDataURL('image/png'). Note that the map object must be set topreserveDrawingBuffer: truein order to export the image. - The frontend may then send the image data to a proxy API. We recommend using a proxy API in this case in order to hide OpenAI API credentials from the public.
- The proxy API sends the image data, along with the credentials, to the OpenAI API vision endpoint, asking for a text description in return.
- Once the text description is received, the proxy API can respond to the frontend with the text description, or request and respond with an audio text-to-speech description.
Use Cases
While image description extraction and text-to-speech are interesting from a technological standpoint on their own, there are some real world use cases that might make this method even more compelling:
- Alt-text generation: the best advice for making visual elements more accessible to users with visual impairments is to provide alt-text that can be read by screen readers. However, there are scenarios where alt-text cannot be generated beforehand. For example, some apps automatically move the map view to a new location based on search criteria. In this case, contextual alt-text can be generated on-the-fly using a method like map-to-speech.
- Vision enhancement: despite a cartographer’s best intentions, there is always a trade-off between detail and legibility. In cases where there are necessary small details on a map, the map-to-speech method may benefit users with low-vision.
Limitations
While the map-to-speech method may be an enhancement of the accessibility of web maps, it is essential to acknowledge certain limitations. One notable constraint is the dependency on external APIs, such as OpenAI’s Vision and Text-to-Speech endpoints. This reliance introduces potential points of failure, including network issues, API rate limits, or service unavailability, which may impact the real-time generation of map descriptions. Additionally, the accuracy of generated descriptions is determined by the underlying machine learning models, meaning there could be instances where the descriptions may not accurately capture map features. Acknowledging these limitations allows for a more nuanced understanding of the technology’s scope and encourages ongoing refinement and improvement in future iterations.
Conclusion
At the heart of this project is an attempt to make geospatial information accessible to all. By harnessing the power of OpenAI’s Vision and Text-to-speech endpoints, we leverage cutting-edge technology to extract detailed descriptions from maps. For users with visual impairments, this opens up a new dimension of understanding, providing rich auditory insights into the geographical landscape.
Our foray into map-to-speech technology is a testament to the power of geospatial expertise focused on inclusivity. By transforming maps into accessible, textual and auditory experiences, we bridge the gap between technology and accessibility, unlocking new horizons for users of all abilities. As we continue our geospatial journey, we’re reminded that every map has a story, and now, more people than ever can consume it.